Memory Throughput을 높이는 방법은 Memory Access Pattern과 관련이 있다.
하나의 warp는 32개의 thread로 구성되어 있다.
따라서 동시에 32개의 요청이 발생할 수 있다.
이 요청의 방식에 따라 성능이 크게 달라질 수 있다.
예를들어 4개의 스레드가 요청이 왔을 때

위 모양보다 아래 모양에서 더 효율적인 성능이 나올 수 있을 것이다.
Global Memory를 살펴보자면
Global Memory의 transcation은 L2 Cache를 통해 이루어지는데
L2 Cache는 최대 32-byte memory를 활용할 수 있다.
(최근에는 L1 Cache를 활용하는 것도 있다. - 128-byte)
그렇다면 Global Memory의 접근 방법을 살펴보자.
- Aligned memory access
- L2 cache : Warp의 메모리 접근 첫 주소가 32-bit * 2n 인 경우
- L1 cache : Warp의 메모리 접근 첫 주소가 128-bit * 2n 인 경우
- Coalesced memory access
- Warp 내 32개 thread가 연속된 메모리 공간을 접근
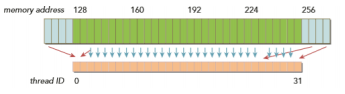
따라서 Aligned 돼있으며 Coalesced 돼있다면 최소한의 접근으로 데이터들을 transcation 할 수 있다.

하지만 그렇지 않다면 3배만금 접근 횟수가 늘어나기 때문에(왼쪽, 오른쪽) 메모리를 3배 더 사용하게 된다.
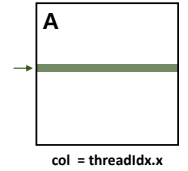
2D block을 표현할 때 threadIdx.x와 threadIdx.y를 row, col로 잡아야 한다.
어떤 것을 row로 잡고 어떤 것을 col로 잡는 것이 효율적일까?
연속되는 32개의 thread가 1개의 warp이라고 했다.
따라서 Matrix 곱셈을 할 때 A Matrix 기준으로 살펴보자.
row = threadIdx.x라면 threadIdx.x의 값들은 col의 길이만큼 메모리 상에서 떨어져 있다.

따라서 이것은 Coalesced Access가 아니다.
하지만 col = threadIdx.x라면 threadIdx.x가 메모리 상에서 연속적으로 이루어져 있다.
따라서 효율이 증가한다.
반대로 B Matrix를 기준으로 보면 각 col 기준으로 접근하기 때문에
이와 반대로 설정해주어야 메모리 상에서 연속적으로 이루어질 수 있다.
구조체를 선언해 줄 때도 Coalesced Access를 고려해보자.
Array of Structures 구조는 같은 데이터 형식끼리 연속적이지 않다.

하지만 Structure of Array 구조는 연속적이다.

이제 Shared Memory를 살펴보자.
Shared memory에는 memory bank가 존재한다. 이는 데이터 접근 통로라고 할 수 있다.
Shared momoery의 bank는 총 32개로 구성되어 있는데
모든 thread가 독립적으로 활용할 수 있도록 하기 위함이다.
bank의 구성 단위는 4byte 또는 8byte 크기로 이루어져 있는데
bank 단위로 독립적이기 때문에 모든 서로 다른 bank가 독립적으로 접근 가능하다.
하지만 하나의 bank에 여러 thread가 접근하는 경우
Bank Conflict가 일어나 문제가 발생할 수 있다.
따라서 같은 Bank에 여러 thread가 온다면 병렬 처리가 되지 않고 직렬화 된다.
결론적으로 Bank Conflict는 속도가 느려지는 원인이 될 수 있다.
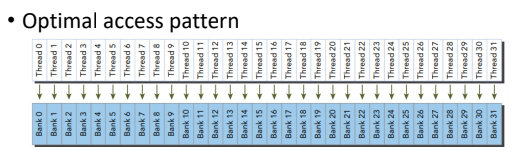

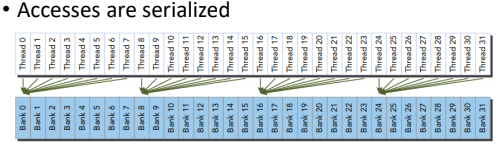
Matrix 곱셈에서도 Bank Conflict 현상을 살펴볼 수 있다.
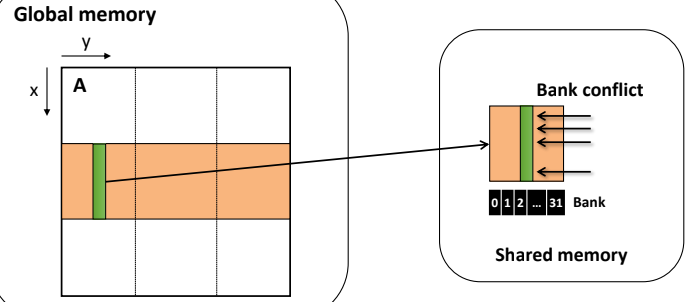
우리가 곱셈하고자 하는 것을 Shared memory로 보낼 때 그대로 올린다면
같은 Bank만 접근하기 때문에 직렬화된다.
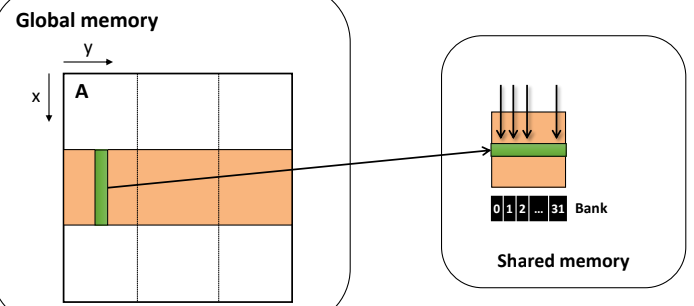
이를 Shared memory에 올릴 때 row, col을 변환해서 올린다면
bank conflict를 해결해낼 수 있다.(성능을 향상시킬 수 있다!)
요약하자면
- Global memory
- aligned 되고 coalesced 된 memory access pattern을 사용해라
- Shared memory
- bank conflict를 피해라
라고 볼 수 있다.
'School Study > Multi Core Programming' 카테고리의 다른 글
| CUDA Stream & Concurrent Execution (0) | 2019.05.21 |
|---|---|
| Synchronization in CUDA (0) | 2019.05.21 |
| CUDA Memory Model (0) | 2019.05.07 |
| CUDA Execution Model (0) | 2019.05.07 |
| CUDA Thread (0) | 2019.04.23 |



