기존 C에서 "Hello World"를 찍기 위한 코드는 다음과 같다.
|
1
2
3
4
|
int main(void) {
printf("Hello World!\n");
return 0;
}
|
cs |
CUDA에서 "Hello World"를 찍기 위한 코드는 다음과 같다.
CUDA를 컴파일하기 위해선 NVIDIA compiler(nvcc)가 필요하다.
|
1
2
3
4
5
6
7
8
|
__global__ void mykernel(void){
// empty kernel
}
int main(void) {
mykernel <<<1,1>>>();
printf("Hello CUDA!\n");
return 0;
}
|
cs |
CUDA의 기본적인 코드들을 살펴보자.
- __host__ → Host에서 호출 가능한 code(기본값)
- __device__ → Device에서 호출 가능한 code
- __global__ → Host에서 GPU를 이용하기 위해 호출하는 code(code → Kernal)
Kernal은 Device thread들의 동작을 정의하는 function이라고 생각하면 된다.
Host가 호출해서 수행을 시작하는데 보통 "<<< >>>" 이런 구문을 통해 호출한다.
CUDA C/C++ file(source code)이나 header를 만들 수 있는데
각각 확장자명이 .cu / .cuh 이다.
따라서 "도구 → 옵션 → 텍스트 편집기 → 파일 확장명"으로 들어가
cu, cuh 파일명을 추가해주는 것이 좋다.

일반적으로 CUDA Programming을 진행하면 Host code와 Device code의 조합으로 이루어져 있다.
- Host : CPU
- host memory : system main memory
- Device : GPU
- device memory : gpu global memory
Host와 Device는 독립적인 하드웨어다. 즉,
서로 다른 메모리 영역을 가지며 또한 서로 비동기적으로 동시에 실행이 가능하다.
일반적인 CUDA Programming Structure를 살펴보자.
- CPU와 GPU는 서로 다른 장치이기 때문에
CPU memory의 Input data를 GPU memory로 복사하는 작업을 거친다. - GPU에서 프로그램을 실행한다.
- 작업이 끝난 데이터를 다시 CPU memory로 옮기는 작업을 거친다.
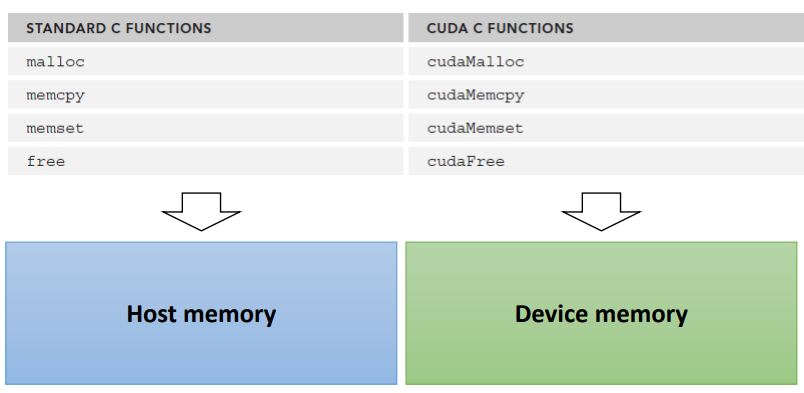
기본적인 Device Memory를 위한 API 함수들은 다음과 같다.
- Device memory allocation / release
- cudaError_t cudaMalloc(void ** ptr, size_t size) : Device 메모리 동적 할당
- cudaError_t cudaFree(void* ptr) : Device 메모리 동적 할당 해제
- Data copy between host and device
- cudaMemcpy(void* dst, const void* src, size_t size, enum cudaMemcpyKind kind)
- cudaMemcpyHostToHost : cpu에서 cpu로 복사
- cudaMemcpyHostToDevice : cpu에서 gpu로 복사
- cudaMemcpyDeviceToHost : gpu에서 cpu로 복사
- cudaMemcpyDeviceToDevice : gpu에서 gpu로 복사
- cudaMemcpyDefault
- cudaMemcpy(void* dst, const void* src, size_t size, enum cudaMemcpyKind kind)
Vector Sum을 CUDA를 적용시켜 GPU를 활용해 구현해보자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define NUM_DATA 512
__global__ void vecAdd(int *_a, int *_b, int *_c)
{
int tID = threadIdx.x;
_c[tID] = _a[tID] + _b[tID];
}
int main(void)
{
int *a, *b, *c;
int *d_a, *d_b, *d_c;
int memSize = sizeof(int)*NUM_DATA;
printf("%d elements, memSize = %d bytes\n", NUM_DATA, memSize);
a = new int[NUM_DATA]; memset(a, 0, memSize);
b = new int[NUM_DATA]; memset(b, 0, memSize);
c = new int[NUM_DATA]; memset(c, 0, memSize);
for (int i = 0; i < NUM_DATA; i++) {
a[i] = rand() % 10;
b[i] = rand() % 10;
}
cudaMalloc(&d_a, memSize);
cudaMalloc(&d_b, memSize);
cudaMalloc(&d_c, memSize);
cudaMemcpy(d_a, a, memSize, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, memSize, cudaMemcpyHostToDevice);
vecAdd <<<1, NUM_DATA >>>(d_a, d_b, d_c);
cudaMemcpy(c, d_c, memSize, cudaMemcpyDeviceToHost);
//check results
bool result = true;
for (int i = 0; i < NUM_DATA; i++) {
if ((a[i] + b[i]) != c[i]) {
printf("[%d] The resutls is not matched! (%d, %d)\n", i, a[i] + b[i], c[i]);
result = false;
}
}
if (result) printf("GPU works well!\n");
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
delete[] a;
delete[] b;
delete[] c;
return 0;
}
|
cs |
먼저 a, b 배열은 임의의 랜덤 값을 넣어두고(정해진 사이즈만큼)
c 배열에 결괏값들을 넣을 것이다.
host memory와 device memory은 독립적으로 동작하기 때문에
각각 따로따로 변수들을 선언해주고 복사해주는 방식으로 진행한다.
host memory는 평소 우리가 짜던 코드처럼 동적 할당해주고 랜덤 값을 넣어주면 되고,
device memory는 cudaMalloc을 통해 할당해주고 cudaMemcpy를 이용해
host memory에서 만든 랜덤 값 그대로 복사해준다.
|
1
2
3
4
5
6
|
cudaMalloc(&d_a, memSize);
cudaMalloc(&d_b, memSize);
cudaMalloc(&d_c, memSize);
cudaMemcpy(d_a, a, memSize, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, memSize, cudaMemcpyHostToDevice);
|
cs |
다음으로 커널을 호출한다.
|
1
|
vecAdd<<<1, NUM_DATA >>>(d_a, d_b, d_c);
|
cs |
여기서 <<< 다음 parameter는 block의 수를 의미한다. 아래에서 더 자세하게 다루겠지만
여기서는 block 1개면 충분한 크기이기 때문에 1로 잡았다.
>>> 전의 parameter(NUM_DATA)는 스레드의 수를 의미한다.
여기서는 벡터 사이즈만큼 스레드를 만들어 각 라인별로 처리하려고 한다.
그렇다면 커널 함수를 살펴보자.
|
1
2
3
4
|
__global__ void vecAdd(int *_a, int *_b, int *_c) {
int tID = threadIdx.x;
_c[tID] = _a[tID] + _b[tID];
}
|
cs |
벡터 사이즈만큼 상당한 양의 스레드가 동시에 처리되기 때문에 각 스레드 별로 구분할 필요가 있다.
따라서 threadIdx(스레드 인덱스)를 통해서 각 스레드를 구분한다.
여기서는 block이 1개이기 때문에 threadIdx만으로 스레드 간 구분이 가능하다.
뒤에서 인덱스에 대해 더 자세하게 다룰 것이다.
|
1
2
3
|
cudaMemcpy(c, d_c, memSize, cudaMemcpyDeviceToHost);
...
cudaFree(d_a); cudaFree(d_b); cudaFree(d_c);
|
cs |
gpu에서 작업을 완료하면 다시 cpu memory로 옮기는 작업이 필요하다.
cudaMemcpy를 통해 복사를 할 수 있으며 gpu에서 cpu로 복사하기 때문에
cudaMemcpyDeviceToHost를 넣어주면 된다.
모든 처리가 완료되고 나면 cudaFree를 통해 gpu memory의 동적 할당을 해제해주자.
cpu memory는 평소 하던 것처럼 delete를 통해 해제해주면 된다.
실제로 CUDA를 활용해 프로그램이 잘 동작하는지 확인했다면
성능이 기존에 비해 빨라졌는지 확인해 볼 필요가 있다.
위 예제를 바탕으로 생각해보자.
성능을 측정하기 위해 어느 부분을 측정해야 할까?
측정 시간은 "계산 + 데이터 변환을 위한 오버헤드"가 될 것이다.
즉, "데이터 전송시간 + 처리 시간"이다.
- 데이터 전송 시간 : cpu gpu간에 데이터 복사하는 과정
- cudaMemcpy(d_a, a, memSize, cudaMemcpyHostToDevice);
- cudaMemcpy(d_b, b, memSize, cudaMemcpyHostToDevice);
- cudaMemcpy(c, d_c, memSize, cudaMemcpyDeviceToHost);
- 처리 시간 : gpu에서 실제 연산하는 과정
- vecAdd<<<1, NUM_DATA >>>(d_a, d_b, d_c);
이를 측정하기 위해 주의할 점이 한 가지 더 있다.
CUDA에서 Kernal은 host와 비동기적으로 실행되기 때문에
kernal이 끝날 때까지 host가 기다리게 해야 정확한 측정이 가능하다.
|
1
2
3
|
// Kernel call
vecAdd<<<1, NUM_DATA >>>(d_a, d_b, d_c);
cudaDeviceSynchronize(); // synchronization function
|
cs |
따라서 Kernel이 호출된 다음 cudaDeviceSyncronize()를 넣어주면 동기화가 가능하다.
CUDA를 활용했을 때와 CPU만을 활용했을 때 차이를 측정해보자.

실제로 시간 측정을 해보면 CPU 버전보다 훨씬 느린 것을 확인할 수 있다.
데이터의 양이 적어 기본 작업보다 적게 나오는 것일까?
그렇다면 데이터의 양을 늘려보자(256 → 1024)

약간 차이가 줄어들긴 했지만 여전히 CPU 버전보다 현저히 느리다.
더 늘린다면 어떻게 될까?

더 늘렸더니 이번엔 정확한 데이터가 나오지 않는다.
왜 이런 현상이 발생할까?
이를 이해하기 위해 CUDA Programming Model에 대한 이해가 필요하다.
우리가 사용하고 있는 GPU는 SIMT Architecture이다.
SIMT Architecture(Single Instruction, Multiple Threads)
Thread들을 그룹 단위로 관리하며, 실행한다.
즉, 모든 thread가 같은 프로그램 코드를 공유하는 것이다.(kernel)
여기서 SIMD와 SIMT의 차이를 생각하자.
SIMD는 하나의 instruction을 여러 개의 data에 적용시키는 것이고,
SIMT는 여러 개의 thread에 적용시키는 것이다.
즉, SIMT에서는 각 작업 항목에 스레드를 개별적으로 분기할 수 있다.
그렇다면, CUDA에서 thread들을 어떻게 관리하는지 계층도를 살펴보자.
CUDA Thread Hierarchy
- Thread
- Basic processing unit
- Warp
- 32 Threads
- Basic exection unit
- Controlled by the same instructions
- Block
- Groups of threads
- Threads in a block have different thread IDs
- threadIdx
- Can be 1D, 2D, or 3D
- Grid
- Groups of blocks
- Blocks in a grid have different block IDs
- blockIdx
- Can be 1D, 2D, or 3D
여기서 주요 개념 용어들을 살펴보자.
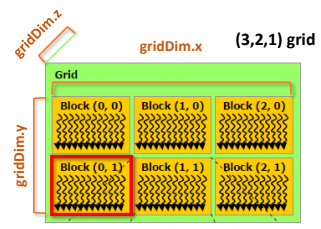

- gridDim
- 현재 그리드의 차원
- Grid 안의 block 수 결정
- blockIdx
- 현재 스레드의 블록 ID
- blockDim
- 현재 블록의 차원
- Block 안의 thread 수 결정
- threadIdx
- Block 안의 현재 스레드의 ID
이렇게 계층이 정해져 있다는 것은 각 공간마다 허용되는 사이즈가 정해져 있다는 소리이다.
즉, 최대로 사이즈를 얼마까지 잡을 수 있는지 미리 정해져 있다.
이것은 CUDA C Programming Guide에 명시되어 있다.

여기서 우리가 앞서 했던 VectorSum 예제의 문제점을 살펴볼 수 있다.
블록마다 최대 threads의 개수는 1024개로 제한되어 있다.
그런데 우리는 Vector 배열의 크기만큼 threads 수를 설정해 주기 때문에
1024개가 넘어가면 CUDA에서 블록 내에 허용하는 최대 thread 개수를 넘어가기 때문에 오류가 발생하는 것이다.
그렇다면 최대 사이즈를 넘지 않게 Block을 여러 개 사용하거나,
Grid까지 활용하는 방식을 알아보자.
먼저 함수를 통해 thread layout을 지정해줄 수 있다.(그리드와 블록의 차원)
dim3 data type은 x, y, z 필드 값을 통해 접근 가능하다.
|
1
2
3
|
dim3 dimGrid(4, 1, 1);
dim3 dimBlock(8, 1, 1);
vecAdd <<<dimGrid, dimBlock>>>(d_a, d_b, d_c);
|
cs |

위 코드를 통해 생성된 thread layout은 위 그림과 같다.
전체가 1개의 Gird가 되는 것이고 Grid에는 4개의 block이 존재한다.
각 block에는 8개의 thread들이 존재하게 된다.
y, z는 모두 1이니 1차원으로 고려한다.
결국 CUDA에서는 사이즈를 잡을지 먼저 결정해야 한다. 이에 따라 성능이나 결과가 달라질 수 있다.
그렇다면 2차원 3차원 block들은 어떻게 표현할까?
결국 메모리 상에는 2차원이든 3차원이든 한 직선에 나열되어 있을 것이다.
어떻게 자신의 thread ID를 찾아가는지 알아보자.
원리는 포인터로 동적 2차원, 3차원 배열에 Access 하는 방법과 같다.
먼저 서로 다른 Block에 존재하는 thread들의 ID들을 어떻게 정하는지 그림과 함께 알아보자.

결국 block 사이즈를 나타내는 blockDim.x를 블록 번지수만큼 곱해준 후,
현재 블록 내의 thread ID를 더해주면 global 하게 고유한 thread ID들을 지정해 줄 수 있다.
이제 이를 바탕으로 위의 VectorSum 예제가 큰 사이즈에서도 동작할 수 있도록 수정해보자.
Kernel
|
1
2
3
4
5
|
__global__ void vecAdd(int *_a, int *_b, int *_c)
{
int tID = blockIdx.x*blockDim.x + threadIdx.x;
_c[tID] = _a[tID] + _b[tID];
}
|
cs |
이제 block이 1개가 아니라 여러 개가 존재할 수 있으므로
kernel에서 global 한 tID를 결정해준다.
Thread layout
|
1
2
3
|
dim3 dimGrid(NUM_DATA / 256, 1, 1);
dim3 dimBlock(256, 1, 1);
vecAdd <<<dimGrid, dimBlock>>>(d_a, d_b, d_c);
|
cs |
각 Block마다 256개의 thread를 가진다고 가정하면 위와 같이 설정할 수 있다.

이젠 1024가 넘어가는 크기에도 정상적으로 계산이 이루어지는 것을 확인할 수 있다.
(물론 아직 성능이 CPU보다 느리다.)
사이즈를 1024 * 1024 * 128 정도로 충분히 크게 늘려보았다.
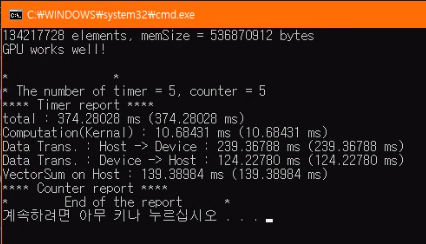
총 걸린 시간은 데이터를 복사하는 시간 때문에 아직 CPU 처리 과정보다 느리지만
단순히 연산 성능만을 비교해보면(kernel vs cpu) 10배 이상 빨라진 것을 확인할 수 있다.
우리는 CUDA를 활용하기 위해 thread layout을 자유자재로 구성할 수 있어야 한다.
먼저 Block 내 global thread ID(TID_IN_BLOCK)은 어떻게 정할까?
- 1D_block_TID
- threadIdx.x
- 2D_block_TID
- (blockDim.x * threadIdx.y) + threadIdx.x
- 3D_block_TID
- ((blockDim.x * blockDim.y) * threadIdx.z) + 2D_block_TID
그렇다면 Grid 내 global thread ID는 어떻게 정할까?
- 1D_grid_TID
- (blockIdx.x * (blockDim.x * blockDim.y * blockDim.z)) + TID_IN BLOCK
- blockDim.x * blockDim.y * blockDim.z = NUM_THREAD_IN_BLOCK
- 2D_grid_TID
- (blockIdx.y * (gridDim.x * NUM_THREAD_IN_BLOCK)) + 1D_grid_TID
- 3D_grid_TID
- (blockIdx.z * (gridDim.x * gridDim.y * NUM_THREAD_IN_BLOCK)) + 2D_grid_TID
이처럼 앞 데이터 형식을 중첩해 나가는 방식으로 점점 차원을 확장시켜 나갈 수 있다.
Thread indexing을 하는 Tip 하나 작성해둔다.
보통 우리가 사용하는 thread의 수가 2의 n제곱이어야 한다.
만약 2의 n제곱이 아닌 경우에는(예를 들어 1025 threads를 사용한다면)
512 크기의 block 3개를 생성한 후
tID가 numThreads를 넘어갈 때 아무것도 안 하고 종료하면 편하다.
|
1
2
3
4
5
6
7
|
__global__ void vecAdd(int numThreads, int …)
{
int tID = blockIdx.x*blockDim.x + threadIdx.x;
if (tID > numThreads)
return;
...
}
|
cs |
'School Study > Multi Core Programming' 카테고리의 다른 글
| CUDA Stream & Concurrent Execution (0) | 2019.05.21 |
|---|---|
| Synchronization in CUDA (0) | 2019.05.21 |
| Maximizing Memory Throughput (0) | 2019.05.14 |
| CUDA Memory Model (0) | 2019.05.07 |
| CUDA Execution Model (0) | 2019.05.07 |



